
Spoiler: I colpevoli sono Amazon, Google, Microsoft (sì, lo so, detto da me suona strano), IBM (aridagli) e tutti quelli che si ostinano a innovare continuamente il modo di “fare le cose” sul cloud.
Premessa: come già successo con il post sul Lifecycle del Software, preparatorio a quello sui Mestieri del DevOps, questo post parlerà delle ultime tendenze per la realizzazione delle applicazioni sul cloud per “preparare il terreno” al successivo, che tratterà invece del fatto che i DevOpper non possono permettersi nemici.
Ergo sarò costretto a essere “moderatamente” più tecnico del solito, ma è necessario per far (provare a far) capire meglio i concetti che vi saranno esposti.
Altra premessa: mi è venuto lunghetto, ma come al solito è uno post “di reazione” alle frustrazioni del momento, per cui mettetevi comodi e abbiate pazienza, in fondo siamo nel fine settimana, che altro avete da fare? Vorrete mica andare al mare con questo caldo?
Mi si chiederà: “Cosa c’entra il Pensiero Analogico con la programmazione in Cloud?”.
Per rispondere a questa domanda dobbiamo risalire a uno dei miei primi incarichi professionali, quando lavoravo per un’azienda che faceva giocare in borsa mezza Italia attraverso i dati del Nasdaq e della Borsa di Milano inviati su una scheda del PC via televideo e via satellite.
All’epoca a casa c’era ancora il modem e ci si collegava a internet (che era uscita dal circuito universitario da pochissimo) e si navigava con Netscape, attraverso i provider come Tiscali, Telecom o Omnitel che, quando andava bene, avevano un numero di telefono urbano da comporre.
Le applicazioni si facevano ancora con i linguaggi “puri”, gli Application Server erano appena nati e funzionavano in modo discontinuo (quando si riusciva a far capire al proprio IT perché potessero essere utili) e il tutto era esercito su server fisici, perché le macchine virtuali erano di là da venire.
(Certo che ne è passato di tempo informatico…).
Il mio direttore tecnico dell’epoca era un Ingegnere Elettronico vecchia scuola, identico nell’aspetto, nei modi di fare (e nei baffi) a Zeb Macahan, che aveva digerito male l’uso dei database: “Ma non facciamo prima a leggere e scrivere su file e basta?” e che ogni volta che avevamo un problema HW sulla “doccia”, il nostro primo rack Oracle con i dischi in raid collegati in fibra, mi ripeteva: “Pensa Analogico”, intendendo che era il caso di cercare di ipotizzare una causa “semplice” del problema prima di imbarcarsi in elucubrazioni e ipotesi che sarebbero costate tempo e fatica e che, magari, non sarebbero approdate a nulla.
Un esempio classico è l’orologio della foto in testa al post, le persone che avevano quel tipo di orologio quando lo trovavano fermo non provavano ad aprirlo e smontarlo:” Perché magari si è rotto un ingranaggio o due ruote dentate non si parlano correttamente”. Semplicemente la prima diagnosi era: “È fermo? Magari per prima cosa provo a caricarlo”.
Infatti, il problema si risolveva quasi sempre staccando e riattaccando uno dei processori su una scheda o togliendo e rimettendo un banco di memoria; aveva ragione lui!!
Inutile dire che questa cosa mi è rimasta attaccata come un imprinting genetico e che, devo dire, mi è servita molto durante la successiva carriera lavorativa. Questa come un’altra massima che ci sarà utile per la comprensione dei concetti di questo post e che è copyright del mio attuale referente (l’alfa e l’omega della mia vita professionale praticamente formano un cerchio “analogico”) e che cita: ”Alla fine di tutto, l’unica vera innovazione dell’Informatica è stata e si riduce alla Subroutine”.
Ma cosa vuol dire:
Pensiero Analogico
Per quanto mi riguarda, il modo migliore per Pensare Analogico (non Digitale, un termine che va di moda ora ma che, secondo me, fa tanto anni 80) è capire effettivamente come funzionano le cose, conoscendone bene il contenuto tecnologico ma tenendo bene in mente a cosa dovrebbero servire, qual’è il loro fine ultimo.
E tutta questa lunga premessa cosa c’entra con la realizzazione delle applicazioni sul Cloud e, soprattutto, con il tema portante di questo blog?
C’entra perché, di suo, la creazione delle applicazioni sul cloud, quando le stesse vengono progettate e realizzate “Cloud Native” (come dicono quelli bravi) sta diventando progressivamente più semplice da fare (e nativamente DevOps, se mi è concesso dirlo) e, in modo inversamente proporzionale, più difficile da spiegare a coloro che sono abituati a sviluppare e gestire il software partendo dal concetto di server, fisico o virtuale che sia.
In parole semplici, l’uso di una macchina virtuale su un ambiente IaaS rende il Lifecycle di un’Applicazione complicato e scomodo esattamente come l’uso nel proprio CED, ma lo capiscono tutti, l’inserimento di un microservizio come funzione AWS Lambda è molto più semplice e veloce, ma quando lo racconti…
… non è che non capiscano, fanno proprio fatica a credere che non li stai prendendo in giro!!!
Perché tutto ciò? Perché la gente pensa sempre a “tutto il cucuzzaro” di un’applicazione (ed è convinta che serva sempre tutto), ma dimentica la grande lezione di Pensare Analogico e per Subroutine.
Traduzione: Per me una pagina web è un insieme di file asci contenute nel browser dell’utente che fa richieste http a delle url, per altri e’ un’applicazione java che contiene:
- delle jsp
- del codice java compilato
- dei framework per gestire il workflow delle pagine
- dei framework per parlare con l’environment
- dei framework per gestire la replica di sessione
- dei framework per gestire la cache
- varie ed eventuali
Che ha bisogno, per funzionare, di:
- un application server
- una java virtual machine
- un server
Ma su questo ci torniamo a breve.
Disclaimer: Gli esempi “tecnologici” che faccio in questo blog sono spesso riferiti ad Amazon AWS, ciò accade non perché siano gli unici che fanno certe cose (anche se sono oggettivamente avanti) ma perché così (al lavoro) non mi si offende nessuno “degli altri”.
Disclaimer 2:
<pierino di turno> “Sì, tutto giusto, però hai semplificato troppo, non hai detto questo, questo e quest’altro” </pierino di turno>
<io> ”Questi dettagli aggiungerebbero qualcosa alla comprensione del tema di fondo?” </io>
<pierino di turno>”No”</pierino di turno>
<io>”Allora fa rima e c’è, stacci”</io>
Benvenuti nel mio mondo.
Dicevamo….
Cercherò di spiegarmi con l’ausilio di qualche immagine e facendo riferimento a una applicazione scritta in java (così parlo di cose su cui ho messo le mani direttamente, avete presente sunxman?).
Prendiamo in esame un’applicazione web classica, che contiene una serie di pagine che, a loro volta, contengono alcune form che, con un workflow complicato a piacere, hanno il compito di far arrivare dei dati dal browser dell’utente al database dell’azienda.
Pensate, ad esempio, alla pagina di registrazione di un sito, piuttosto che alla pagina di richiesta di calcolo del tasso di interesse di un mutuo bancario.
Pensiero Analogico: L’utente finale vede una pagina su un browser, inserisce dei dati nei campi della pagina, preme invio, vede il risultato della sua richiesta. I dati della sua richiesta vengono salvati.
Subroutine: l’algoritmo di calcolo, che riceve (IN) i dati economici e restituisce (OUT) il risultato persistendolo su un DBMS.
Come si sarebbe fatta questa cosa quando sono nati gli application server?
Si creava un’applicazione che conteneva al suo interno tutto, dal codice che creava l’html finale della pagina utente alla Subroutine di calcolo alle classi che dovevano gestire ogni scambio tra quello che faceva l’utente e quello che faceva l’applicazione, ci si dotava di un capace server, ci si installava sopra, in sequenza:
- Sistema operativo
- Java Virtual Machine
- Application server preferito
- Librerie di comunicazione con il Database
- L’applicazione con dentro la nostra Subroutine
Il tutto è riassunto nella figura seguente.
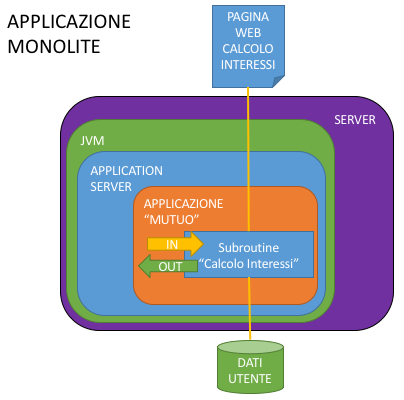
Scalabilità di questa cosa? Si poteva fare solo “in blocco” duplicando tutto lo stack tecnologico e “proxando” le richieste distribuendole ai singoli nodi a livello di bilanciamento di frontiera.
Manutenibilità? Anche cambiare un colore di un’etichetta sulla pagina implicava rideployare tutta l’applicazione su tutti i server, con i problemi di errori di regressione che immaginate (e probabilmente ricordate).
Cosa si è pensato di fare allora? Separiamo i livelli, mettiamo tutto ciò che riguarda il Front End da una parte e tutto ciò che riguarda il Back End dall’altra, creando la situazione che vedete nella figura qui sotto.
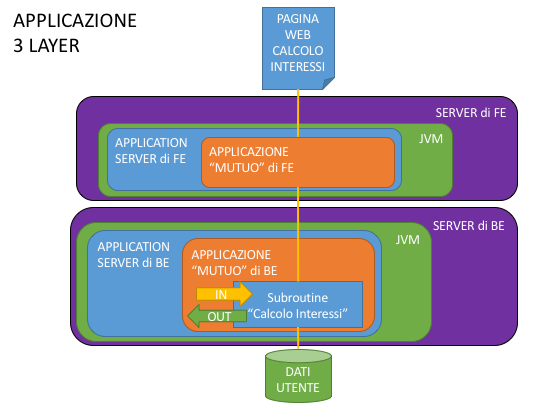
I più accorti nella separazione avranno messo, per quanto possibile, la logica di business sul Back End (la nostra amica Subroutine) alleggerendo il Front End e creando i presupposti per l’evoluzione che vi racconto dopo.
Scalabilità: Ora si poteva provare a scalare un layer in modo differente rispetto all’altro, ma sempre “tutto il cucuzzaro” bisognava tirare su per avere un altro nodo del layer di appartenenza, sempre bilanciando “da fuori” le chiamate, quindi ogni nodo in più comportava una riconfigurazione del bilanciatore stesso.
Manutenibilità: Valgono le stesse considerazioni della scalabilità, una modifica comportava comunque il re-deploy completo di uno dei layer, con tutti i rischi e le controindicazioni del caso.
E qui ci siamo fermati.
Nel senso che in molte aree IT del nostro paese (in quello romano di sicuro) questo è “lo stato dell’arte”.
Sono i posti in cui il mantra è: ”Non avrai altro dio all’infuori di me, xxx” (Inserire al posto delle x la marca di un Application Server a piacere).
Nonché del: ”Non si possono fare le applicazioni senza un Application Server”.
D’altronde come dargli torno, lo dice anche il nome: APPLICATION Server …..
Peccato che, come diceva Roland di Gilead:
“Il mondo è andato avanti”
Cosa è successo? Steve Jobs ha convinto tutti che fare certe cose direttamente sul telefonino “è fico” e la gente ci ha provato e si è resa conto che in realtà, più che fico è estremamente comodo.
Sono nate le App e le pagine “responsive” e ci si è resi conto che un’applicazione che, tramite servizi REST, di botto poteva essere acceduta da milioni di device doveva scalare in modo “un po’ più furbo”, doveva poter essere sviluppata in modo un po’ più modulare e indipendente e doveva poter evolvere (molto) velocemente.
E quindi? Quindi hanno accelerato l’evoluzione del cloud, superando la visione limitante dello IaaS e si sono ricordati della Subroutine, l’hanno ribattezzata Microservizio e ci hanno cucito intorno un environment di esercizio estremamente leggero e velocemente scalabile, il Container (Docker se chiedete a me).
E la nostra pagina web?
Lì hanno Pensato Analogico; si sono detti:” Ma se noi abbiamo già dei servizi che fanno tutto il “lavoro sporco” per le App Mobile, perché non facciamo la stessa cosa con le pagine web? Tanto alla fine sempre una form l’utente deve riempire e i dati che passa sempre quelli sono”.
E quindi sono nate le Sigle Page Application FATTE DI PURO HTML e JAVASCRIPT!!
Che vuol dire? Vuol dire che dalle webapp per la quale era necessario avere un Application Server (e tutto il cucuzzaro) per dare la pagina all’Utente, siamo passati a UNA DIRECTORY DI FILE ASCII, erogabili, al limite, direttamente da un server http.
In pratica sono arrivati a pensarla come me.
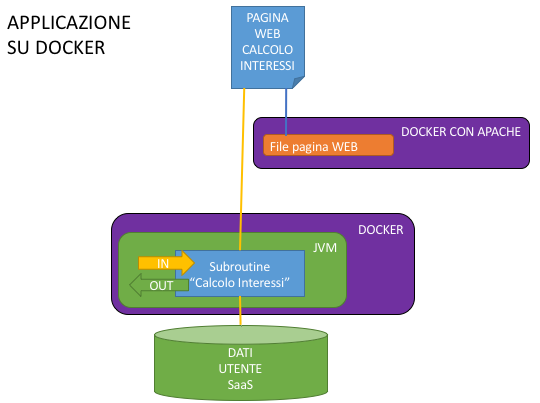
Il tutto ha dato l’occasione di fare architetture come quelle della figura, che consentono una scalabilità REALMENTE differenziata per microserv.., scusate, per singolo Container Subroutine e per singolo container di frontend e una manutenibilità, se si seguono le regole della corretta gestione degli stati delle chiamate e della coerenza delle firme dei servizi, decisamente superiore a quella del paradigma precedente, perché con una gestione accorta (vogliamo dire DevOps?) dello sviluppo, il redeploy tipicamente arriva a interessare solo lo specifico microservizio di un’applicazione, mantenendo inalterati e in linea tutti gli altri che la compongono.
Chiaramente stiamo parlando di Container orchestrati da uno strumento che fa quello di mestiere (es. Kubernetes), non “gestiti a linea di comando” come vorrebbero fare gli irriducibili delle macchine virtuali.
E già qui sono dolori, perché vallo a spiegare che puoi mettere la logica di un’intera webapp direttamente nel browser dell’utente, farla erogare senza dover pagare licenze e farla scalare (e bilanciare) in modo automatico da un orchestratore.
“Sì, vabbè, ma il Back End? Per quello comunque un Container con all’interno un Application Server per ospitare la tua Subroutine ti serve!”
Potrei anche essere d’accordo per Subroutine (leggi applicazioni) complesse, che richiedono una gestione della persistenza e delle transazioni accorta, che sfruttano realmente alcune delle facilities applicative (non infrastrutturali, a scalare i Container, ribadisco, devono pensarci gli orchestratori) messe a disposizione dagli AS, ma se il mio microservizio deve solo “leggere e scrivere e fare di conto”, cosa ci dovrei fare con tutta la potenza di fuoco di un Application Server? Cosa mi darebbe oltre a un aumento considerevole delle dimensioni del mio Container?
Per questo motivo le nuove tendenze sono quelle di far funzionare i microservizi su Container che contengono lo stretto necessario per il loro funzionamento, nel nostro caso una JVM e un framework “di contorno” come, ad esempio, Spring Boot.
Ovviamente tra il Docker Apache che contiene la pagina html e il Docker con l’Application Server che contiene la web application java che implementa la pagina, ci sono varie sfumature di grigio, ma mi servivano gli estremi per farvi capire il salto mentale (analogico) che è necessario per capire, per comprendere a pieno, la differenza “culturale” di un’architettura a Docker rispetto a quelle tradizionali.
Però ai signori del Cloud ancora non bastava (sti maledetti).
Si sono detti: “Abbiamo sollevato i nostri clienti dal problema della gestione delle macchine, che senso ha costringerli a gestirsi i Container?”.
Pensa che ti ripensa, si sono ri-ricordati della Subroutine, hanno deciso di “farla splendere di luce propria” e si sono “inventati” i sistemi Serverless.
Cioè?
Cioè hanno tirato su dei servizi Cloud che consentono l’esecuzione “secca” di funzioni direttamente dal codice sorgente, che si attivano a eventi (leggi invocazioni dei servizi) e che ci “liberano” dal doversi preoccupare di come i servizi scalano e in quali ambienti operano, perché vengono pagati “a chiamata” senza canone base (al contrario dei Docker e dello IaaS).
Ovviamente, da buoni spacciatori, un certo numero di chiamate iniziali le hanno messe a disposizione in modo gratuito.
La conseguenza è la possibilità di erogare la nostra cara applicazione di calcolo del mutuo come nella figura.
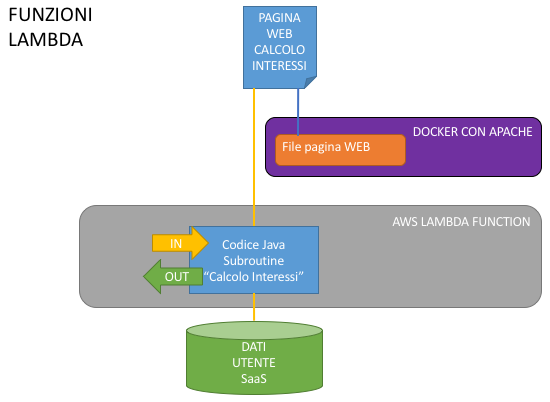
Pensare che tutto questo è stato possibile ricordandosi che, alla fine di tutte le “elucubrazioni” mentali, una pagina web non è altro che un file html che “chiede cose” e vive INTERAMENTE sul browser dell’Utente (Pensiero Analogico) e che quelle cose che la pagina chiede gli si possono dare direttamente, tramite una Subroutine che espone una url, senza accatastarci sopra altre cose che non servono, ma solo perché “è tradizione”.
E il cerchio si chiude.
Alla prossima.
Link interessanti sul passaggio dal monolite ai microservizi:
- From Monolith to Microservice Architecture on Kubernetes, part 1 — The Api Gateway
- Refactoring a Monolith into Microservices
Se è riferito alle Subroutine, è esattamente così.
Io non invecchio, mi rigenero.
Dott. Who.